全局屏蔽敏感词,速通 OBS、OpenCV、PaddleOCR
直播国际联机游戏如 Apex 容易“炸房”,可使用其“直播模式”将玩家名称转为四位数字,但如 B 站的直播平台存在四位数字的屏蔽词,开了 Apex 直播模式仍被“炸房”的情况在 B 站屡见不鲜。未提供“直播模式”的同类游戏直播风险显然更大。
自然就存在全局屏蔽指定文字的需求。
实现效果样例
左侧为 OBS 预览窗口,虚线框为录制 GIF 时录制工具的窗口。
屏蔽“给我变”
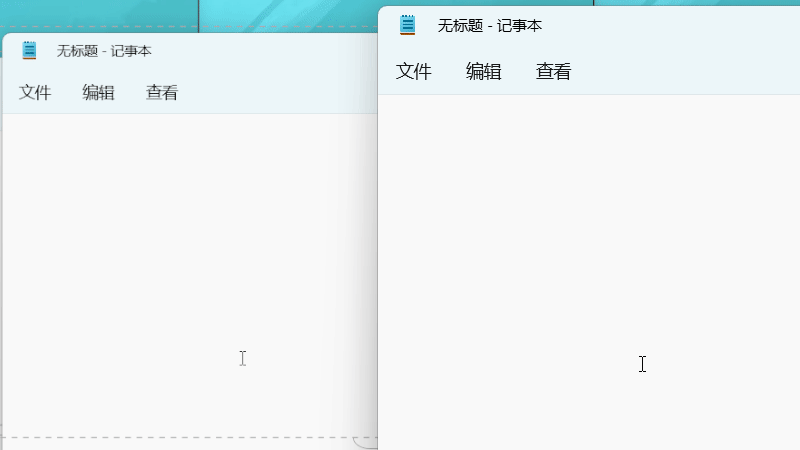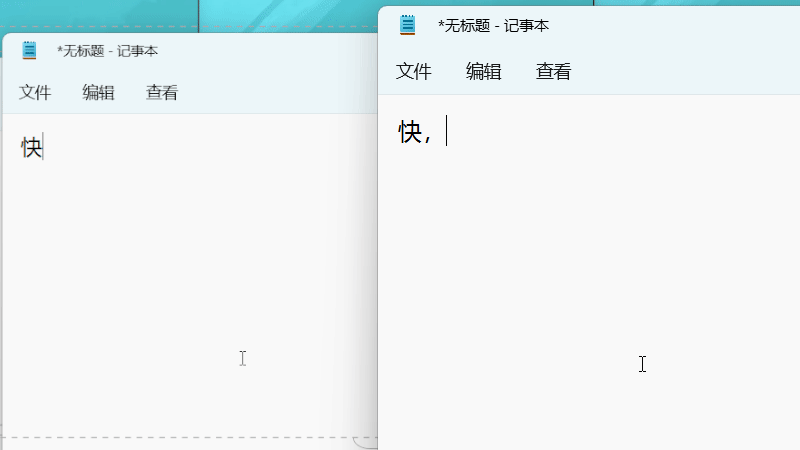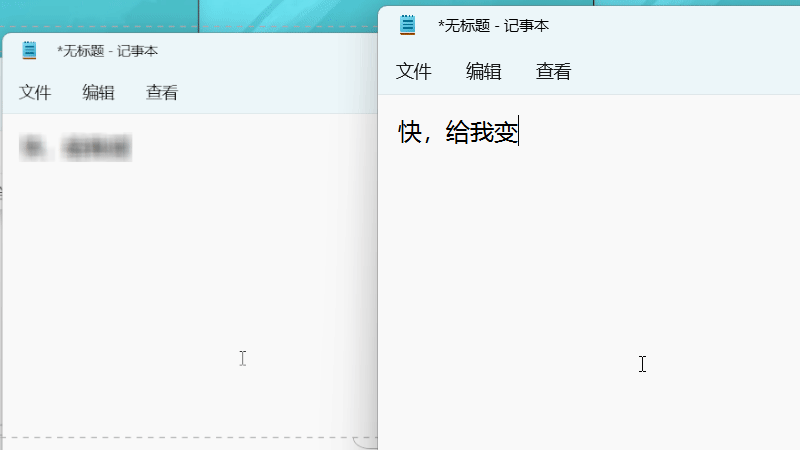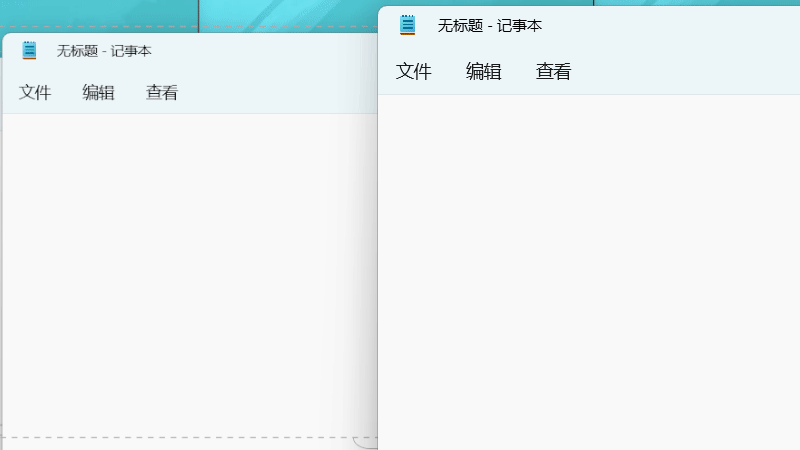
为覆盖约 50ms 的最大 OCR 耗时,配置了 100ms 的渲染延迟。
屏蔽“探路者”

为覆盖约 100ms 的最大 OCR 耗时,配置了 200ms 的渲染延迟。
选定方案
直播业最常用的捕获工具应该是 OBS Studio (官网 / GitHub / API 文档),文字识别在内的计算机视觉模型最常用的图像处理工具应该是 OpenCV(官网 / GitHub / API 文档),中文识别模型速度最快、准确度最高的应该是飞桨(官网 / GitHub / API 文档)上的 PaddleOCR(GitHub),最终选定的方案便是 OBS + OpenCV + PaddleOCR。
考虑到
- OBS 支持插件,在单个渲染线程中处理各插件对输出帧的变换,使用 Direct3D 11 / OpenGL 捕获图形,
- OpenCV 可以配合 OpenCL 转换 Direct3D 11 / OpenGL 图像为 UMat 进行进一步处理,
- 一次 1080P 屏幕的 OCR 往往需要数百毫秒,
制定 OBS 插件执行流程大体如下:

其中,
- “延迟队列”的长度根据实际需要由用户配置,使得帧的屏蔽结果与帧的输出时机匹配。例如,当刷新率为 60fps,OCR 最大耗时约 500ms 时,用户可以配置 30 帧的延迟队列。当某帧 OCR 仅耗时 100ms 时,可以等待到对应延迟帧被取出时再将该帧屏蔽区域存入共享屏蔽区域。
- “处理队列”的长度与“识别线程”的数量相等,“识别线程”的数量也由用户根据实际需要配置。
- “屏蔽区域”根据用户需求可包含多个“帧屏蔽区域”,提高帧屏蔽区域的滞留时间。
后文记录项目编写过程中部分踩过的坑和进行的部分性能优化。
初识 OBS Studio
乍一看很复杂,深入看很有条理。
入门 OBS 插件编写
OBS 官方的插件编写建议有一定误导性。官方强烈建议使用 obs-plugintemplate 插件模板进行插件开发,该模板仓库文档主要描述如何通过 GitHub Actions 编译,通过仓库 Actions 页面下载生成的文件。这意味着开发过程中想测试一下得 commit 上传 GitHub 等待 GitHub 生成后从网页里下回来,再解压到 OBS 插件安装目录,还很难配合调试工具调试。这对于很小型很简单的 OBS 插件、已在某操作系统上测试需要在另一操作系统上发布的插件可能有用,毕竟不需要配置对应的本地环境;而对于稍复杂点的新项目,则完全不现实。
建议参考 obs-plugintemplate 仓库内实际作用的相关脚本、官方的插件编写文档、第三方开源 OBS 插件,配置完整的本地的 OBS 开发环境。
捕获、输出 OBS 图像
OBS 官方库中的 GPU Delay 插件(plugins/obs-filters/gpu-delay.c)可以延迟视频源。通过阅读它的源码,我们知道可以使用 gs_texrender_t 类和相关函数在渲染线程中获取和输出帧。下面的示例就来自该插件,每行的具体含义不完全清楚。
精简的帧捕获示例,放置于 obs_source_info.video_render 函数:
// 所要获取的 OBS 渲染帧对象
// 仅以普通 SDR 源为例,未考虑 HDR、高精度 SDR 屏
gs_texrender_t *texrender = gs_texrender_create(GS_RGBA, GS_ZS_NONE);
// context 即插件创建时收到的 obs_source_t* 参数
obs_source_t *target = obs_filter_get_target(context);
obs_source_t *parent = obs_filter_get_parent(context);
uint32_t width = obs_source_get_base_width(target);
uint32_t height = obs_source_get_base_height(target);
gs_blend_state_push();
gs_blend_function(GS_BLEND_ONE, GS_BLEND_ZERO);
if (gs_texrender_begin(texrender, width, height)) {
uint32_t parent_flags = obs_source_get_output_flags(target);
bool custom_draw = (parent_flags & OBS_SOURCE_CUSTOM_DRAW) != 0;
bool async = (parent_flags & OBS_SOURCE_ASYNC) != 0;
struct vec4 clear_color;
vec4_zero(&clear_color);
gs_clear(GS_CLEAR_COLOR, &clear_color, 0.0f, 0);
gs_ortho(0.0f, (float)width, 0.0f, (float)height, -100.0f, 100.0f);
if (target == parent && !custom_draw && !async)
obs_source_default_render(target);
else
obs_source_video_render(target);
gs_texrender_end(texrender);
}
gs_blend_state_pop();可以通过 gs_texrender_get_texture 获取渲染帧对象 gs_texrender_t 内包裹的图像对象 gs_texture_t。
gs_texture_t *texture = gs_texrender_get_texture(texrender);进一步通过 gs_texture_get_obj 获取 OBS 图像对象包装的 DirectX / OpenGL 贴图。
// Windows 上 ID3D11Texture2D*
// MacOS / Linux 上 GLuint*
auto base_texture = (ID3D11Texture2D*)gs_texture_get_obj(texture);精简的图像绘制示例,同上放置于 obs_source_info.video_render 函数:
const bool prev_srgb = gs_framebuffer_srgb_enabled();
gs_enable_framebuffer_srgb(true);
static gs_effect_t *effect = obs_get_base_effect(OBS_EFFECT_DEFAULT);
gs_effect_set_texture_srgb(
gs_effect_get_param_by_name(effect, "image"), texture);
while (gs_effect_loop(effect, "Draw"))
gs_draw_sprite(texture, 0, width, height);
gs_enable_framebuffer_srgb(prev_srgb);适时预转换 OBS 贴图
使用 OpenGL 时(即 MacOS / Linux 系统上),OBS 所使用的各类贴图都可以直接被第三方工具解析。但使用 DirectX 时(即 Windows 系统上),对普通 SDR 源,OBS 会使用 Typeless 自定义贴图渲染帧,这类贴图对于 OpenCV 等第三方工具来说格式未知,不能直接转换。
可以使用下面这样的中间贴图让 OBS 预转换上述贴图为兼容格式。
// GS_RGBA 对应 DXGI_FORMAT_R8G8B8A8_TYPELESS,
// GS_RGBA_UNORM 对应 DXGI_FORMAT_R8G8B8A8_UNORM,
// 后者可以被其他工具解析
// 中间贴图,GS_SHARED_TEX 可以加速后续转换
gs_texture_t *unormTexture = gs_texture_create(width, height, GS_RGBA_UNORM, 1, nullptr, GS_SHARED_TEX | GS_RENDER_TARGET);
// 将 texture 复制到 unormTexture,该函数内含相关格式转换
gs_copy_texture(/* dst */ unormTexture, /* src */ texture);
// 获取包裹的 DXGI_FORMAT_R8G8B8A8_UNORM 贴图
auto base_texture = (ID3D11Texture2D*)gs_texture_get_obj(unormTexture);
// 第三方工具进一步转换 base_texture
// ...HDR、高精度 SDR 源在 OBS DirectX 中对应 DXGI_FORMAT_R16G16B16A16_FLOAT 格式,可以直接被 OpenCV 等工具解析,没有上述问题。
踩坑 OpenCV
原以为 OpenCV 这样知名的库随便写性能都会优化得很好,用起来发现还是需要相当的精心调教的。
适时使用 UMat
使用 UMat 即使用 OpenCV Transparent API 包装的 OpenCL 贴图,可大幅加速生成输出帧时用到的图像处理(如 blur)操作,减少对 OBS 帧率的影响。
目前,成熟的中文文字识别需要两步完成,一步通过 DB 类模型找出文本框,另一步通过 CRNN 类模型识别各框内文本。这两步的模型对输入图像有不同的预处理要求。
在识别线程中,是否也适合使用 UMat 预处理图像数据传递给 OCR 各模型?在作者的电脑上,DB 模型识别 960P 以上的图像时 UMat 的预处理略微快过 Mat 的预处理,但在进行 CRNN 模型的预处理时 UMat 的 warpPerspective 太慢,对多数图像远远慢过 Mat。考虑到 DB 模型本身就跑得很快、用户为了整体速度很可能使用插件提供的裁切功能致使识别图像不达阈值,本插件均使用 Mat 对各 OCR 相关模型进行图像预处理。
适时使用中间 UMat 加速 cvtColor
OpenCV 官方不建议混用 Mat 和 UMat,在转换时需要额外小心。
由于渲染线程使用 UMat,而识别线程使用 Mat,我们需要完成一次类型转换。同时,OBS 使用的颜色格式为 RGBA,OCR 模型使用 BGR,需要一次颜色格式转换。那么,直接使用 cvtColor 一次性将 UMat RGBA 转换为 Mat BGR 是否可行?可行,但不推荐。
定义使用一个中间 UMat 进行上述转换比单次 cvtColor 快约 1.9 倍。当此中间 UMat 分配的空间被有效地重用时,快约 2.9 倍。
// UMat RGBA -> Mat BGR
cv::UMat umatRGBA;
cv::Mat matBGR;
// `cvtColor` 同时处理颜色格式和类型,慢
cv::cvtColor(umatRGBA, matBGR, cv::COLOR_RGBA2BGR);
// `cvtColor` 处理颜色格式 + `copyTo` 处理类型,快
cv::UMat umatBGR; // 中间 UMat
cv::cvtColor(umatRGBA, umatBGR, cv::COLOR_RGBA2BGR);
umatBGR.copyTo(matBGR);阅读 cvtColor 的源码实现可以发现,目前 cvtColor 只在第二个参数为 UMat 时判断是否应用相关 OpenCL 加速,这应该是造成上述速度差异的主要原因。
适时使用 UMat::copyTo 替代 UMat::setTo
UMat::setTo 当前的源码实现不会根据参数贴图的类型优化 OpenCL 参数,在参数贴图和目标贴图同为 UMat 时比 UMat::copyTo 慢得多。
cv::UMat source;
cv::UMat target;
// 不推荐,慢
target.setTo(source);
// 推荐,快
source.copyTo(target);使用 copyTo 替代 clone
clone 的源码实现(Mat::clone / UMat::clone)非常简单,就是对 copyTo 的简单包装。使用 copyTo 替代可以方便重用已经分配的贴图内存。
// 不推荐
cv::UMat cloned = texture.clone();
// 推荐,方便优化
cv::UMat cloned;
texture.copyTo(cloned);
// 合适时,恰当重用内存
thread_local cv::UMat cloned;
texture.copyTo(cloned);适时 getMat 加速绘制
阅读各绘制函数的源码实现,多数对于 UMat 会在内部转换为 Mat 处理。在连续使用绘制函数时,为减少转换次数,应提前使用 getMat 取得对应 Mat,然后转而绘制修改该 Mat。该 Mat 在释放(析构或调用 Mat::release)时会自动将结果写回原来的 UMat。
注意,原 UMat 在其 getMat 取得的 Mat 释放前不得被读取、修改、释放,否则可能引发运行错误。除了手动 Mat::release,也可以将这类 Mat 对象和相关操作一起放到外部函数或子级作用域中,就像 RAII 风格的 mutex 上锁。例如,
// 要操作的 UMat 贴图
cv::UMat umat;
{
cv::Mat mat = umat.getMat(cv::ACCESS_WRITE);
// 绘制示例文本
cv::putText(
mat,
"Example",
cv::Point(10, 20),
cv::FONT_HERSHEY_SIMPLEX,
2,
cv::Scalar(0, 255, 0));
// 其他绘制操作
// ...
}
// 其他操作
// ...慎用 fillPoly
fillPoly 是 OpenCV 内唯一可以一次性填充多个任意多边形的函数,但多数时候它不是这项工作的最佳选择。fillPoly 会跨多边形地计算所有边包围区域的交集,被偶数次覆盖的区域不会被填充。
例如,使用 fillPoly 填充大小相等的左上、左下、右上三个在中心相交的正方形,
cv::Mat img = cv::Mat::zeros(200, 200, CV_32FC1);
std::vector<std::vector<cv::Point>> polygons;
polygons.push_back({ { 25, 25 }, { 125, 25 }, { 125, 125 }, { 25, 125} });
polygons.push_back({ { 75, 25 }, { 175, 25 }, { 175, 125 }, { 75, 125} });
polygons.push_back({ { 25, 75 }, { 125, 75 }, { 125, 175 }, { 25, 175} });
cv::fillPoly(img, polygons, cv::Scalar(1));会得到:
这处处理容易被忽视,容易浪费计算资源生成不期望的结果。一般情况下填充多个多边形,自己写 fillConvexPoly 循环最快而且最准确。
// 数个要填充的单调多边形
std::vector<std::vector<cv::Point>> blocks;
for (const auto& block : blocks)
{
// 不使用可以直接接收 block 的 InputArray 重载,
// 因为其当前的源码实现是将 InputArray 转换为 Mat,
// 然后再根据 Mat 地址转而使用此指针重载,步骤多余
cv::fillConvexPoly(texture, block.data(), block.size(), cv::Scalar(0, 255, 0));
}fillConvexPoly 很快,但支持的多边形种类有限。当需要绘制 fillConvexPoly 不支持的多边形,而且多个所绘制的多边形之间的交集需要被保留时,可以转而使用一次只画一个的 fillPoly 循环。
// 数个要填充的任意多边形
std::vector<std::vector<cv::Point>> blocks;
// 一次 fillPoly 一个,
// 以保证 被多个多边形覆盖的区域 也被填充
for (const auto& block : blocks)
{
auto pt = block.data();
auto npt = (int)block.size();
// 不使用可以直接接收 { block } 的
// InputArrayOfArrays 重载,理同 fillConvexPoly
cv::fillPoly(maskMat, &pt, &npt, 1, cv::Scalar(0, 255, 0));
}不修改跨线程的贴图
多线程同时读取、修改 Mat 或 UMat 对象不安全。项目测试中,渲染线程对帧进行的任意修改都非常容易导致识别线程转换 UMat 得到的 Mat 局部空白。这个问题当然可以通过 mutex 解决,但是会偶尔阻塞渲染线程一段时间。
为了在保持性能的同时解决这个问题,在绘制输出帧时,并不是将屏蔽框绘制到输入帧(此处代指流程图中的延迟帧)后输出输入帧,而是将输入帧通过一个“反向的”遮罩复制到屏蔽图后输出屏蔽图。例如,
// 取得的输入帧(此处代指流程图中的延迟帧)
cv::UMat input_texture;
// 取得的屏蔽区域
std::vector<std::vector<cv::Point>> blocks;
// static 用于重用贴图内存
// .create() 仅在大小或格式变化时重新分配内存
static cv::UMat output_texture;
static cv::UMat mask;
// 设置屏蔽图,以纯绿色为例
output_texture.create(height, width, CV_8UC4);
output_texture = cv::Scalar(0, 255, 0, 255);
// 遮罩所有区域
mask.create(height, width, CV_8UC1);
mask = cv::Scalar(255);
// 忽略屏蔽区域
{
cv::Mat maskMat = mask.getMat(cv::ACCESS_WRITE);
for (const auto& block : blocks)
{
cv::fillConvexPoly(maskMat, block.data(), block.size(), cv::Scalar(0));
}
}
// 遮罩复制输入帧到屏蔽图上
input_texture.copyTo(output_texture, mask);
// 输出屏蔽图
// ...贴图池
尽可能重用已分配内存、避免贴图拷贝在本项目中非常重要。60fps 要求每帧在约 16ms 内完成,更高的帧率要求更紧,而 1080P Mat、UMat 的每次内存分配、拷贝本地测试耗时约 1ms,更高的分辨率处理更慢。
一张贴图可能同时被渲染模块、处理模块、延迟模块引用,处理模块销毁其引用的时间不确定;项目频繁捕获新贴图;同时需要的贴图数量很有限。这样的情况下,最符合直觉的简单效率的方案是创建如内存池的“贴图池”,渲染线程在获取帧时向贴图池申请,贴图池从最老的(最可能空闲的)大小格式匹配的贴图开始检查,返回仅池中有引用、外部均已销毁的贴图,并将该贴图标记为最新。若没有这样的贴图(池为空或者贴图均被外部引用),则在池中新建一个并返回。
在 OpenCV 当前版本中,这样的“仅池中有引用”的贴图可以根据“引用计数”是否为 1 来分辨。Mat 可以通过 UMatData::refcount 取得引用计数,UMat 可以通过 UMatData::urefcount 取得,不过这两个属性没有正式的文档说明,在未来版本中可能失效。UMatData 可以通过 Mat::u、UMat::u 取得。
别用 OpenCV DNN 做 OCR
OpenCV 底层有自带的 DNN 机器学习模块,顶层有相应文字识别 API,但不支持 TensorRT 加速,不支持 Dynamic Shape,支持的 OCR 模型识别中文的准确率太低。速度也慢效果也差,作者最开始不知道,浪费了不少时间。
接入 PaddleOCR
PaddleOCR 使用 Paddle Inference 推理时运行得最快最准确。
踩坑 VS 2022 编译 Paddle Inference
这一步没有必要,使用官方预编译包或者指定的 VS 2019 自编译就没有问题。
作者是早些时间因为太馋 .NET 7 提前把 VS 升为了 2022 Preview 版本,懒得再回退或者另外装 2019 了。
不过还好,这一步没记错的话只遇到了一个坑,飞桨目前依赖的 protobuf 版本比较老,该版本 protobuf 在 src/google/protobuf/stubs/hash.h 用到了 VS 2022 17.4 开始被标记为删除的一些 Hash 相关 API,在编译时会生成很多类似下面的错误,
error C2039: 'hash_compare': is not a member of 'std'实测可以在生成前修改飞桨 protobuf 相关 cmake 文件,添加 _SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS 定义,来绕过此错误。
优化 PaddleOCR 的 C++ 部署
PaddleOCR 官方提供的 C++ 部署样例中的图像预处理、后处理部分有许多处可以优化加速的地方。
- 去除对源图像的多余复制。项目可以确保图像不会在处理过程中被修改,因此许多函数中的这些复制都是多余的。
- 适时复用中间图像的内存。项目解析的图像的尺寸多数时候保持不变,因此可以将一些函数内的中间图像设为线程局部变量(添加
thread_local关键字)复用已分配的内存。 - 去除文本框排序步骤。在识别并裁切出图片中的各处文本子贴图后,PaddleOCR 会将它们从上到下、从左到右排序。项目不依赖各文本框的位置顺序,因此此处排序是多余的。
- 适时跳过贴图数值映射。对 HDR、高精度 SDR 源,OBS 使用浮点数保存帧贴图,数值范围和推理模型一致,不需要进行数值映射转换。
使用 TensorRT
TensorRT 在本地测试时能节省 20-50% 的 OCR 解析时间,但因为首次启动往往需要等待数分钟等原因,被设计为本插件的一个默认关闭的可选选项。
基于实操体验,对 Paddle Inference C++ TensorRT 配置文档作一些简单的补充说明:
- 使用
Config::SetOptimCacheDir设置的缓存路径同样适用于 TensorRT 的静态引擎优化信息。 - 使用
Predictor::Clone克隆产生的预测器不参与Config::CollectShapeRangeInfo的 shape 信息存储文件的生成。 - 使用
Config::CollectShapeRangeInfo时 TensorRT 引擎不参与实际预测,同时会关闭许多优化,很占内存。 Config::EnableTunedTensorRtDynamicShape的“运行时重建 TensorRT 引擎”功能在输入 shape 超过 tune 范围时,除了会重建正在运行的 TensorRT 引擎,也会更新所使用的 shape 信息存储文件。每次重建所需时间和首次启动时间相当,没有什么优化,应当尽力避免。
过滤文本
敏感词过滤搜索算法有很多,比较随意地选定了 cjgdev/aho_corasick 的 Aho-Corasick 算法实现。发现对上万个敏感词的搜索时间都足够快,便没有动力再琢磨其他的实现、其他的算法作对比。
注意保持敏感词存储文件的编码与文字辨别模型字库文件的编码一致。
结语
标题的“速通”作者实际用了约 20 天,因为实际方案和各种细节不像本文是经过精简的一下就选定的,而是逐步踩坑逐步改出来的,多花了很多时间,其中编写初版插件 5 天,OpenCV DNN 性能优化 3 天,抛弃 OpenCV DNN 改用 PaddlePaddle 5 天,最后各类优化和方案调整花去了最多的时间。
相较于周围的同学感觉已经很快很快了,就是不知道对于从业人员来说算不算慢,因为还是大三没工作过。在做这个之前我连 CMake 是啥都不知道,C++ 各类指针、互斥锁等基础的东西根本没用过。平时学校几乎不教实战,全是理论,真的感觉不自己摸点什么本科生出来啥都不会。